先说说Moments 这个极简朋友圈项目吧
直达:kingwrcy/moments: 极简朋友圈
小声哔哔 对的,自己去看文档吧,部署的话相当简单,使用docker-compose一键部署速度的很,而且现在的版本是作者使用GO重构的,轻快的很嘞。
项目好用是好用,但是说说最终还是想让一些陌生人说说的,不然怎么叫说说呢,于是就想同步到博客的说说界面,刚好前几天将博客迁移到了hexo的anzhiyu主题,想看看有没有现成的教程直接部署一下完事了,奈何,不知道是搜寻方法不对还是怎么的,反正就是没找到,在柳神的博上看到了他已经实现了这样的同步,但是他是原Butterfly主题改的,然后翻教程也没翻到,评论也没来得及回我,好吧昨天才问的就是心急想赶紧部署出来 没办法,又回头去看Moments 文档,发现它有api,这个就有点搞头了。
搞搞看吧!
Moments配置 第一步:修改 Moments 的 Docker Compose 配置(允许跨域来源)
登录 1Panel 面板,左侧菜单找到「容器」→ 找到你的moments容器,点击「编辑」(或在「应用」里找到 Moments 点击「配置」)。
找到「环境变量」设置,添加一条跨域配置:
变量名:CORS_ORIGIN
变量值:https://你的博客域名(比如https://blog.example.com,如果是 HTTP 则写http://...)
如果想允许所有域名(不推荐,有安全风险),可以填*
如果你是docker-compose 配置的(推荐),在编排中的JWT_KEY:下方添加两行配置代码(注意缩进,格式对齐):
1 2 ENABLE_SWAGGER: "true" CORS_ORIGIN: https://blog.mzxi.cn
保存配置,重启 Moments 容器(点击「重启」按钮)
第二步:在 1Panel 的反向代理中添加跨域响应头(推荐添加) 如果第一步配置后仍有跨域问题,需要在反向代理层(Nginx)补充跨域头:
在 1Panel 左侧菜单找到「网站」→ 找到你配置的 Moments 域名(比如moments.example.com),点击「配置」→「反向代理」。
找到对应的反向代理规则(指向 Moments 容器 3000 端口的那条),点击「编辑」。
在「高级配置」或「自定义配置」中,添加以下跨域相关的响应头(直接复制粘贴):
1 2 3 4 5 6 7 8 add_header 'Access-Control-Allow-Origin' 'https://blog.mzxi.cn' always; add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS' always; add_header 'Access-Control-Allow-Headers' 'Authorization, Content-Type' always; add_header 'Access-Control-Allow-Credentials' 'true' always;
保存配置,1Panel 会自动重载 Nginx 配置。
Moments的API配置获取测试 获取参数: 1 2 3 4 5 6 7 8 9 MOMENTS_API_URL = "你的域名/api/memo/list" JWT_TOKEN = "你的x-api-token" ESSAY_YML_PATH = "E:/source/_data/essay.yml"
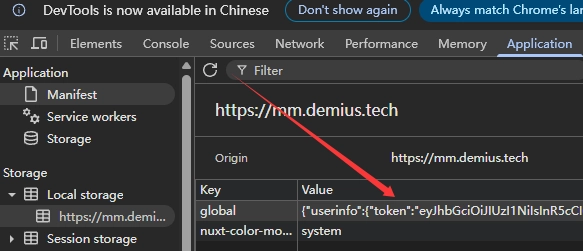
上面三个参数根据你自己的修改,说一下第二个参数的获取方式:
登录你的Moments 后,打开F12,刷新一下网站,如图就是你的x-api-token了:
API验证 这里使用的是postman开源项目Hoppscotch • Open source API development ecosystem • Hoppscotch
Requesting body里选application/vnd.api.json,输入一下内容:
1 { "page" : 1 , "size" : 10 , "showType" : 1 }
Request header里填:
1 2 3 x-api-token :你的token Content -Type :application/json
最后点右边的发送(send),下方应该返回类似 以下内容:
1 { "code" : 0 , "data" : { "list" : [ { "id" : 1 , "username" : "mzxi" , "nickname" : "码字·兮兮" , "avatarUrl" : "/upload/cb979ca8273" , "slogan" : "时间就是以生命,Life is money,Money is time" , "coverUrl" : "/upload/8a9d2" } , "imgConfigs" : null } ] , "total" : 2 } }
代表通讯成功,如果显示无法网络无法链接什么的换个代理或者啥的,就是下面返回的内容中手动切换一下,算是小问题。
本地部署执行 在博客根目录(Hexo的根目录)下创建sync_moments_advanced.py文件,将以下代码放入(记得上面三个从参数修改成你自己的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 import requestsimport jsonimport datetimeimport osfrom ruamel.yaml import YAML MOMENTS_API_URL = "你的域名/api/memo/list" JWT_TOKEN = "你的x-api-token" ESSAY_YML_PATH = "E:/source/_data/essay.yml" headers = { "x-api-token" : JWT_TOKEN, "Content-Type" : "application/json" } def fetch_moments_data (): """获取API动态数据""" try : payload = {"page" : 1 , "size" : 100 , "showType" : 1 } response = requests.post( MOMENTS_API_URL, headers=headers, data=json.dumps(payload) ) response.raise_for_status() resp_json = response.json() moments_list = resp_json.get("data" , {}).get("list" , []) print (f"✅ 成功获取{len (moments_list)} 条动态" ) return moments_list except Exception as e: print (f"❌ API请求失败:{str (e)} " ) return [] def parse_special_content (item ): """解析扩展内容""" special_fields = {} ext_str = item.get("ext" , "{}" ) try : ext_data = json.loads(ext_str) except : ext_data = {} if ext_data.get("music" ) and ext_data["music" ].get("id" ): special_fields["aplayer" ] = { "server" : ext_data["music" ].get("server" , "netease" ), "id" : ext_data["music" ].get("id" , "" ) } if ext_data.get("video" ) and ext_data["video" ].get("value" ): special_fields["video" ] = [ext_data["video" ]["value" ]] if item.get("location" ): special_fields["address" ] = item["location" ] return special_fields def convert_to_essay_item (item ): """转换为essay格式""" try : createdAt = item.get("createdAt" , "" ) dt = datetime.datetime.fromisoformat(createdAt.replace("Z" , "+00:00" )) date_str = dt.strftime("%Y/%m/%d" ) except : date_str = "2025/01/01" content = item.get("content" , "" ).replace("\n" , "<br>" ) user_info = item.get("user" , {}) essay_item = { "content" : content, "date" : date_str, "from" : user_info.get("nickname" , "mzxi" ) } essay_item.update(parse_special_content(item)) return essay_item def update_essay_yml (new_items ): """保留注释更新essay_list""" if not os.path.exists(ESSAY_YML_PATH): print (f"❌ 未找到文件:{ESSAY_YML_PATH} " ) return False yaml = YAML() yaml.preserve_quotes = True yaml.indent(mapping=2 , sequence=4 , offset=2 ) try : with open (ESSAY_YML_PATH, "r" , encoding="utf-8" ) as f: data = yaml.load(f) if not isinstance (data, list ) or len (data) == 0 or not isinstance (data[0 ], dict ): print ("❌ 文件格式错误:需为列表且第一项为配置字典" ) return False config = data[0 ] print ("✅ 成功读取文件(保留所有注释)" ) except Exception as e: print (f"❌ 读取文件失败:{str (e)} " ) return False old_essay_list = config.get("essay_list" , []) if not isinstance (old_essay_list, list ): old_essay_list = [] print (f"✅ 读取到原有{len (old_essay_list)} 条短文" ) existing_keys = set () for item in old_essay_list: if isinstance (item, dict ): content_key = item.get("content" , "" )[:30 ] date_key = item.get("date" , "" ) existing_keys.add(f"{content_key} _{date_key} " ) new_essay_items = [] for item in new_items: content_key = item.get("content" , "" )[:30 ] date_key = item.get("date" , "" ) item_key = f"{content_key} _{date_key} " if item_key not in existing_keys: new_essay_items.append(item) existing_keys.add(item_key) if not new_essay_items: print ("ℹ️ 无新动态需要同步" ) return True updated_essay_list = new_essay_items + old_essay_list limit = config.get("limit" , 30 ) config["essay_list" ] = updated_essay_list[:limit] try : with open (ESSAY_YML_PATH, "w" , encoding="utf-8" ) as f: yaml.dump(data, f) print (f"✅ 同步完成:新增{len (new_essay_items)} 条,共{len (config['essay_list' ])} 条" ) return True except Exception as e: print (f"❌ 写入文件失败:{str (e)} " ) return False def main (): print ("=" * 60 ) print (f"📅 同步开始:{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S' )} " ) moments_data = fetch_moments_data() if not moments_data: print ("📅 同步终止" ) return new_essay_items = [convert_to_essay_item(item) for item in moments_data] new_essay_items.sort(key=lambda x: x["date" ], reverse=True ) update_essay_yml(new_essay_items) print (f"📅 同步结束:{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S' )} " ) print ("=" * 60 ) if __name__ == "__main__" : main()
使用步骤
安装依赖 (首次使用):
1 pip install requests ruamel.yaml
运行脚本 :
1 python sync_moments_with_comments.py
效果验证 运行后控制台应该出现类似这样的信息(如果你已经在Moments 上发布过动态):
1 2 3 4 5 6 7 8 ============================================================ 📅 同步开始:2025-09-16 22:10:01 ✅ 成功获取4条动态 ✅ 成功读取文件(保留所有注释) ✅ 读取到原有4条短文 ✅ 同步完成:新增1条,共5条 📅 同步结束:2025-09-16 22:10:03 ============================================================
查看 essay.yml,相关动态信息应该也已经写入啦!
云端定时任务执行 上面说的是本地部署博客的同时顺手拉一下动态更新,但是如果平时我们随心情发布的动态没法及时更新是不是很不美了,这就需要计划任务了
计划任务对于不同情况部署方式不同,我这边因为使用的服务器,面板部署比较方便,其他朋友可以使用免费的Github部署等等,网上教程搜搜很多,这里就不写了
1panel 面板定时任务部署Moments极简朋友圈同步到Hexo博客说说 这个方案其实是一开始的想法,主要数据服务都抓在自己手里比较安心,只要服务器厂家靠谱点就行,另外目前实现的方案对于2-2 的小水管不太友好,比如我这小破机器,在拉取数据后同步生成页面的过程会瞬间将CPU 拉满,直接卡爆了!
如果你只跑这个博客一个项目的话没什么问题,自己玩玩,如果是还有其他项目,建议更换服务器吧!
还有个缺点是既然是定时的计划任务,那么就有时效性,并不是实时更新的,尤其是在每次更新都会炸掉CPU 的情况下,时效总是拉长,替代方案目前有几个,但是还没有试过,后面再说
目前我的计划任务定了两个小时更新一次,也就是说如果你Moments 的动态发布后,博客的说说数据同步是晚两个小时的,这个根据你计划任务的周期来定,反正目前我这小水管实时是别想了,另外生成也要时间,毕竟是静态博客
好了,哔哔了很多,下面看教程吧!
前置准备(新手必看) 在开始前,确保你有以下东西:
一台服务器 (示例:系统 Ubuntu/Debian);1Panel 面板 (已安装);Hexo 博客源码 (本地已调好,包含essay.yml数据源和主题(如安知鱼));Moments API 信息 (API 地址、JWT Token,用于获取动态数据,前面步骤);基础命令行知识 (会复制粘贴命令即可)
第一步:搭建核心环境(Python+Node.js) 需要两个环境:Python 用于同步 Moments 数据,Node.js 用于生成 Hexo 静态文件。
1. 搭建 Python 环境(虚拟环境,隔离依赖) 目的:避免 Python 库冲突,新手优先用虚拟环境
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 apt update -y && apt install python3 python3-pip python3-venv -y mkdir -p /opt/scripts && cd /opt/scriptspython3 -m venv venv source venv/bin/activatepip install requests ruamel.yaml
2. 搭建 Node.js 环境(nvm 管理版本,避免冲突) 目的:灵活切换 Node 版本,适配 Hexo 7.3.0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bash source ~/.bashrcnvm install 22.16.0 nvm use 22.16.0 node -v npm -v
第二步:准备核心脚本(2 个脚本搞定全流程) 需要两个脚本:Python同步脚本(拉取 Moments 数据到essay.yml)和Shell总控脚本(串联同步、生成、复制全流程)。
1. 编写 Python 同步脚本(sync_moments_advanced.py) 作用:从 Moments API 拉取数据,更新 Hexo 的essay.yml(保留注释),原理在上面本地部署执行拉取的时候是一样的
1 2 3 4 5 cd /opt/blog-sourcenano sync_moments_advanced.py
2. 编写 Shell 总控脚本(sync-moments-blog.sh) 作用:串联 “切换 Node 版本→同步数据→生成静态文件→复制到 1Panel→清理” 全流程
1 2 3 4 5 cd /opt/scriptsnano sync-moments-blog.sh
粘贴以下代码(把1.配置参数里所有路径改成你自己的!):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 import requests import datetime from ruamel.yaml import YAML import sys import hashlib # 用于计算内容MD5,精准比对内容 # -------------------------- 1. 核心配置(替换为你的实际信息) -------------------------- # -------------------------- 新手必改:3处核心配置 -------------------------- MOMENTS_API = "你的实际API域名/api/memo/list" # ❗ 必须替换为你的实际API地址(如https://api.example.com/moments) JWT_TOKEN = "eyJhbGc58_4kLQfo" # ❗ 替换为你的实际令牌(若API不需要令牌,可改为空字符串:JWT_TOKEN = "") ESSAY_YML_PATH = "/opt/blog-source/source/_data/essay.yml" # ✅ 这个路径通常不用改,确认存在即可 def get_content_md5(content): """计算内容的MD5哈希(确保内容完全一致才返回相同值)""" # 去除内容前后空格,避免因空格差异误判 clean_content = content.strip() # 计算MD5(需编码为UTF-8) md5_obj = hashlib.md5(clean_content.encode("utf-8")) return md5_obj.hexdigest() # 返回32位MD5字符串 def convert_to_timestamp(iso_time): """将API的ISO时间(如2025-09-17T04:48:14.768737624+08:00)转换为毫秒级时间戳(统一精度)""" try: # 解析带时区的ISO时间 dt = datetime.datetime.fromisoformat(iso_time) # 转换为毫秒级时间戳(乘以1000,取整避免小数位差异) timestamp_ms = int(dt.timestamp() * 1000) return timestamp_ms except Exception as e: print(f"⚠️ 时间格式转换失败:{iso_time},错误:{str(e)}") return None def fetch_moments_data(): """拉取API数据:适配{"code":0,"data":{"list":[...]}}结构""" headers = { "x-api-token": JWT_TOKEN, "Content-Type": "application/json", "User-Agent": "Mozilla/5.0 (Linux; Android 10; SM-G975F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Mobile Safari/537.36" } payload = {"page": 1, "size": 100, "showType": 1} try: response = requests.post(MOMENTS_API, headers=headers, json=payload, timeout=10) response.raise_for_status() api_result = response.json() if api_result.get("code") != 0: print(f"❌ API错误:code={api_result.get('code')},msg={api_result.get('msg')}") sys.exit(1) moments_list = api_result.get("data", {}).get("list", []) total = api_result.get("data", {}).get("total", 0) print(f"✅ API请求成功:共{total}条动态(本次返回{len(moments_list)}条)") return moments_list except Exception as e: print(f"❌ 拉取动态失败:{str(e)}") sys.exit(1) def load_existing_essay(): """加载现有essay.yml,提取“时间戳+内容MD5”作为去重key""" yaml = YAML() yaml.preserve_quotes = True yaml.indent(mapping=2, sequence=4, offset=2) try: with open(ESSAY_YML_PATH, "r", encoding="utf-8") as f: essay_config = yaml.load(f) if not isinstance(essay_config, list) or len(essay_config) == 0: print(f"❌ essay.yml格式错误:需为列表结构") sys.exit(1) existing_essay_list = essay_config[0].get("essay_list", []) existing_keys = set() # 存储去重key:"时间戳_ms_内容MD5" for old_item in existing_essay_list: # 提取现有动态的“时间戳”和“内容”(首次执行时可能没有timestamp,跳过) old_timestamp = old_item.get("timestamp_ms") old_content = old_item.get("content", "").strip() if old_timestamp and old_content: # 生成去重key:时间戳+内容MD5 old_content_md5 = get_content_md5(old_content) old_key = f"{old_timestamp}_{old_content_md5}" existing_keys.add(old_key) print(f"✅ 加载现有essay.yml:共{len(existing_essay_list)}条短文,已提取{len(existing_keys)}个去重key") return essay_config, existing_essay_list, existing_keys except FileNotFoundError: print(f"❌ 未找到essay.yml:{ESSAY_YML_PATH}") sys.exit(1) except Exception as e: print(f"❌ 读取essay.yml错误:{str(e)}") sys.exit(1) def deduplicate_and_merge(moments_list, existing_essay_list, existing_keys): """去重逻辑:时间戳(毫秒级)+ 内容MD5 完全一致才视为重复""" new_essay_items = [] for moment in moments_list: # 1. 提取API字段 content = moment.get("content", "").strip() created_at = moment.get("createdAt", "") # ISO时间 location = moment.get("location", "") nickname = moment.get("user", {}).get("nickname", "mzxi") # 跳过无效动态(无内容或无时间) if not content or not created_at: print(f"ℹ️ 跳过无效动态:content={content[:20]}...,createdAt={created_at}") continue # 2. 转换时间戳(毫秒级,统一精度) timestamp_ms = convert_to_timestamp(created_at) if not timestamp_ms: continue # 时间转换失败,跳过 # 3. 生成去重key:时间戳+内容MD5 content_md5 = get_content_md5(content) new_key = f"{timestamp_ms}_{content_md5}" # 4. 去重判断:key不在现有集合中,视为新动态 if new_key in existing_keys: print(f"ℹ️ 重复动态:时间戳={timestamp_ms},内容MD5={content_md5[:8]}...,已跳过") continue # 5. 处理显示日期(YYYY/MM/DD) try: dt = datetime.datetime.fromisoformat(created_at) show_date = dt.strftime("%Y/%m/%d") except Exception as e: show_date = "未知日期" print(f"⚠️ 日期格式处理失败:{created_at},错误:{str(e)}") # 6. 构造新动态(含timestamp_ms,用于下次去重) new_item = { "timestamp_ms": timestamp_ms, # 存储毫秒级时间戳(去重用) "content": content.replace("\n", "<br>"), # 换行转HTML "date": show_date, # 页面显示日期 "from": nickname, # 作者昵称 "address": location # 位置(无则为空) } new_essay_items.append(new_item) existing_keys.add(new_key) # 新增key到集合,避免同批次重复 # 7. 合并:新动态放前面(最新动态显示在顶部) merged_essay_list = new_essay_items + existing_essay_list print(f"ℹ️ 去重完成:新增{len(new_essay_items)}条动态,合并后共{len(merged_essay_list)}条") return new_essay_items, merged_essay_list def save_essay_yml(essay_config, merged_essay_list): """保存更新后的essay.yml,保留注释""" yaml = YAML() yaml.preserve_quotes = True yaml.indent(mapping=2, sequence=4, offset=2) try: essay_config[0]["essay_list"] = merged_essay_list with open(ESSAY_YML_PATH, "w", encoding="utf-8") as f: yaml.dump(essay_config, f) print(f"✅ 保存essay.yml成功:{ESSAY_YML_PATH}") return True except Exception as e: print(f"❌ 保存essay.yml错误:{str(e)}(需权限:chmod 644 {ESSAY_YML_PATH})") sys.exit(1) if __name__ == "__main__": print("=" * 60) start_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") print(f"📅 同步开始:{start_time}") # 1. 拉取API数据 moments_data = fetch_moments_data() if not moments_data: print(f"ℹ️ 无动态数据,流程结束") print(f"📅 同步结束:{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}") print("=" * 60) sys.exit(0) # 2. 加载现有essay.yml及去重key essay_config, existing_essay, existing_keys = load_existing_essay() # 3. 去重合并 new_items, merged_list = deduplicate_and_merge(moments_data, existing_essay, existing_keys) # 4. 处理结果 if len(new_items) == 0: print(f"ℹ️ 无新动态(已去重)") print(f"📅 同步结束:{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}") print("=" * 60) sys.exit(0) # 无新动态,返回0 else: save_essay_yml(essay_config, merged_list) print(f"📅 同步结束:{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}") print("=" * 60) sys.exit(2) # 有新动态,返回2
在本脚本目录下进入终端,给脚本加执行权限(必须!否则无法运行):
1 chmod +x /opt/scripts/sync-moments-blog.sh
第三步:测试脚本(确保全流程能跑通) 一定要先手动测试,再设置定时任务,避免后续排查麻烦,在sync-moments-blog.sh脚本所在目录进入终端,执行命令:
1 2 /opt/scripts/sync-moments-blog.sh
成功标志(日志里要看到这 3 句):
✅ 同步完成:新增X条动态(或ℹ️ 无新动态需要同步);Generated: essay/index.html(Hexo 生成成功);✅ 成功更新:/opt/1panel/.../essay/index.html(复制成功);🎉 全流程完成!(最终成功)。
失败处理:
若提示 “模块缺失”:激活 Python 虚拟环境(source /opt/scripts/venv/bin/activate),用pip install 缺失模块名安装;
若提示 “essay 页面没找到”:回头检查主题的essay.enable是否设为true;
若提示 “权限不足”:执行chmod -R 755 /opt/scripts /opt/blog-source赋予权限。
第四步:1Panel 设置定时任务(实现全自动) 测试成功后,用 1Panel 设置定时任务,让脚本每天自动运行
左侧菜单点击「计划任务」→ 点击「创建计划任务」;
按以下参数填写(照抄,仅需改 “执行周期”):
将以下代码粘贴到脚本内容框里:
1 2 3 4 5 6 7 (export NVM_DIR="/root/.nvm" && \ echo "=== 1. 开始加载nvm ===" && \[ -s "$NVM_DIR /nvm.sh" ] && \. "$NVM_DIR /nvm.sh" && echo "=== 2. nvm加载成功 ===" || echo "=== 2. nvm加载失败 ===" && \ echo "=== 3. 添加node路径到PATH ===" && export PATH="$(nvm which node | xargs dirname) :$PATH " && \echo "=== 4. 查看node版本 ===" && node -v && \echo "=== 5. 开始执行脚本 ===" && \/opt/scripts/sync-moments-blog.sh) 2>&1 | tee -a /opt/scripts/sync-log.log
点击「确认」保存任务。
第五步:测试定时任务
在定时任务列表中,找到刚创建的任务,点击右侧「执行」;
等待 1-2 分钟(取决于服务器性能,俺只能苦涩一笑,老子每次手动得等五分钟左右!这中间服务器完全处于崩塌状态!!求赞助一台56核心_64G内存_960GSSD_500M上/下_的物理机!!
若日志显示🎉 全流程完成!,说明定时任务正常。
贴一下计划任务成功执行的日志吧:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 === 1. 开始加载nvm === === 2. nvm加载成功 === === 3. 添加node路径到PATH === === 4. 查看node版本 === v22.16.0 === 5. 开始执行脚本 === [2025-09-17 09:50:31] 1/7 切换Node.js版本到22.16.0... Now using node v22.16.0 (npm v10.9.2) [2025-09-17 09:50:32] 2/7 同步Moments数据... ============================================================ 📅 同步开始:2025-09-17 09:50:32 ✅ API请求成功:共18条动态(本次返回18条) ✅ 加载现有essay.yml:共37条短文,已提取17个去重key ℹ️ 重复动态:时间戳=1758073097903,内容MD5=174eb632...,已跳过 ℹ️ 重复动态:时间戳=1758073082422,内容MD5=db06c78d...,已跳过 ℹ️ 重复动态:时间戳=1758008318729,内容MD5=c8983108...,已跳过 ℹ️ 重复动态:时间戳=1757948011048,内容MD5=188bb0fc...,已跳过 ℹ️ 去重完成:新增1条动态,合并后共38条 ✅ 保存essay.yml成功:/opt/blog-source/source/_data/essay.yml 📅 同步结束:2025-09-17 09:50:32 ============================================================ [2025-09-17 09:50:32] 3/7 检测essay.yml是否变更... [2025-09-17 09:50:32] 4/7 生成静态文件(CPU已限流)... [2025-09-17 09:50:32] 5/7 过滤文件:仅保留essay目录... /opt/scripts/sync-moments-blog.sh: line 72: cd : /opt/blog-source/public: No such file or directory INFO Validating config INFO =================================================================== █████╗ ███╗ ██╗███████╗██╗ ██╗██╗██╗ ██╗██╗ ██╗ ██╔══██╗████╗ ██║╚══███╔╝██║ ██║██║╚██╗ ██╔╝██║ ██║ ███████║██╔██╗ ██║ ███╔╝ ███████║██║ ╚████╔╝ ██║ ██║ ██╔══██║██║╚██╗██║ ███╔╝ ██╔══██║██║ ╚██╔╝ ██║ ██║ ██║ ██║██║ ╚████║███████╗██║ ██║██║ ██║ ╚██████╔╝ ╚═╝ ╚═╝╚═╝ ╚═══╝╚══════╝╚═╝ ╚═╝╚═╝ ╚═╝ ╚═════╝ 1.6.14 =================================================================== INFO Start processing INFO hexo-blog-encrypt: encrypting "最新 TVBox 教程:从安装到使用,一篇就够(文章密码请关注公众号发送关键字:TVBox)" based on the password configured in Front-matter with theme: default. INFO 2 bangumis have been loaded INFO Files loaded in 20 s INFO Generated: essay/index.html ...这是省略号... INFO Generated: img/friend_404.gif INFO Generated: img/tx.png INFO Generated: images/author.jpg INFO 167 files generated in 10 min Process 325171 dead! Process 325171 detected
总的来说,建议本地使用脚本拉取好了,不然的话,真的会卡!!!!!
新的免费白嫖方案(随机调整) 如果你是直接跳转到这里看的,嗯,夸你聪明,因为上面定时方案不仅有问题而且还不太好用,会卡这个就是最大的BUG ,新的方案换个思路,我们家小业小的,那就吃大户嘛!嘿嘿,把整个Hexo 的过程全部放到Github 上去,让大户来造车子,咱们等它造好了之后去把轮子借来用就行,嗯,不对,是模仿一个轮子!
思路比较简单,不过还是需要会一点基础命令,能大概知道哪里对哪里即可,剩下的就是复制粘贴
同步脚本和下载脚本 Moments极简朋友圈同步安知鱼主题说说.7z密码:48t2
解压密码博客主页到公众号回复关键词(Moments极简朋友圈同步安知鱼主题说说)拿哦嗯,不给白嫖,只能我白嫖别人,嘻嘻嘻嘻嘻嘻嘻嘻嘻
拿到了里面有三个文件:
sync_essay_to_github.py (同步脚本)
download_essay_html.sh (下载脚本)
generate-essay.yml (github workflows自动构建脚本)
最简单的办法是把这三个脚本全喂给你的AI,随便哪个都行,哦,对了,喂之前先给段提示词:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 ### 提示词模板(朋友需先补充【】中的个人信息,再发给 AI 助手): #### 一、我的需求背景 我需要在自己的服务器上跑通两个关联脚本,实现「Hexo 博客说说页面自动同步更新」,具体是: 1. Python 同步脚本:从 Moments API 拉取全量动态数据 → 覆盖本地 essay.yml → 推送到 GitHub 触发 Hexo 构建 2. Shell 下载脚本:从 GitHub 下载构建好的 essay/index.html → 覆盖服务器博客的说说页面 现在两个脚本的原始代码已拿到,但需要适配我的环境,希望你帮我: - 检查脚本需修改的配置项是否正确 - 生成 step-by-step 的执行步骤(从环境准备到定时任务) - 遇到报错时能指导排查(比如权限、API 访问、Git 推送问题) #### 二、我的服务器与账号信息(需补充) 1. 服务器系统:【例如:Ubuntu 22.04 / CentOS 8】 2. 我的 GitHub 信息: - 用户名:【例如:xxx123】 - 博客仓库名:【例如:my-hexo-blog】(仓库已克隆到服务器) - GitHub PAT(已生成,有 repo 权限):【仅需告知 “已准备好,会按指引设置环境变量”,无需透露具体值】 3. Moments API 信息: - API 地址:【例如:[https://my-moments-api.com/](https://my-moments-api.com/api/list)[api/l](https://my-moments-api.com/api/list)[ist](https://my-moments-api.com/api/list)】 - API 访问令牌(ESSAY_JWT_TOKEN):【仅需告知 “已准备好,会按指引设置环境变量”】 4. 服务器上的关键路径(需补充): - Hexo 博客根目录:【例如:/home/xxx/my-hexo-blog】 - essay.yml 存放路径:【例如:/home/xxx/my-hexo-blog/source/_data/essay.yml】 - 博客说说页面(index.html)本地路径:【例如:/var/www/blog/essay/index.html】 - GitHub 仓库在服务器的克隆目录:【例如:/home/xxx/my-hexo-blog】 #### 三、两个脚本的核心功能与需适配点(供你参考) ##### 1. Python 同步脚本(核心逻辑:API 拉取→覆盖 YML→推 GitHub) 需适配的配置项(原始脚本里的硬编码): - 环境变量:ESSAY_JWT_TOKEN、GITHUB_PAT(已准备好,需指导设置) - 固定路径:MOMENTS_API_URL(我的 API 地址)、ESSAY_YML_PATH(我的 essay.yml 路径)、GITHUB_REPO_DIR(我的 GitHub 仓库克隆目录) - GitHub 配置:Git 用户名 / 邮箱(我的 GitHub 账号信息)、GitHub 仓库推送地址(适配我的用户名和仓库名) ##### 2. Shell 下载脚本(核心逻辑:下载 HTML→覆盖本地页面) 需适配的配置项: - GITHUB_PAGES_URL:我的 GitHub Pages 上 essay/index.html 的地址(【例如:[https://xxx123.github](https://xxx123.github.io/my-hexo-blog/essay/index.html)[.io/m](https://xxx123.github.io/my-hexo-blog/essay/index.html)[y-hex](https://xxx123.github.io/my-hexo-blog/essay/index.html)[o-blo](https://xxx123.github.io/my-hexo-blog/essay/index.html)[g/ess](https://xxx123.github.io/my-hexo-blog/essay/index.html)[ay/in](https://xxx123.github.io/my-hexo-blog/essay/index.html)[dex.h](https://xxx123.github.io/my-hexo-blog/essay/index.html)[tml](https://xxx123.github.io/my-hexo-blog/essay/index.html)】) - LOCAL_ESSAY_PATH:我的服务器上博客说说页面的实际路径(已填在上面) - LOG_FILE:日志存放路径(可默认或建议一个安全路径) #### 四、我的疑问与期望 1. 先确认:我的服务器需要提前装哪些依赖(比如 Python 版本、pip 库、curl 等)? 2. 环境变量设置:临时生效和永久生效的步骤分别是什么?担心重启服务器后变量丢失 3. 脚本执行顺序:是先测试 Python 脚本,再测试 Shell 脚本吗?测试时需要注意什么(比如备份原始文件)? 4. 定时任务:同步脚本 10 分钟一次、下载脚本 5 分钟一次,crontab 的配置语句怎么写? 5. 报错排查:如果遇到 “API 拉取失败”“Git 推送被拒”“文件替换权限不足”,分别该查什么? #### 五、补充说明 - 我对 Linux 命令有基础了解,但复杂配置(如权限、环境变量)需要详细指引 - 两个脚本需关联运行,定时任务的时间差(同步 10 分钟、下载 5 分钟)是否合理?是否需要调整? 请基于以上信息,帮我梳理从 “环境准备→脚本修改→测试执行→定时任务设置” 的完整流程,确保我能一步步跑通,实现说说页面自动同步。
给朋友的使用说明 1 2 3 4 1. 先让朋友把【】中的内容替换成自己的实际信息(比如服务器系统、GitHub 用户名、真实路径),绝对不要透露 PAT 和 API 令牌的具体值,只需告知 AI 助手 “已准备好” 即可 2. 朋友将填充后的提示词直接发给 AI 助手,AI 会基于他的实际环境生成个性化指南(比如如果是 Ubuntu 系统,会推荐apt命令;如果是 CentOS,会推荐yum命令) 3. 遇到报错时,朋友可补充 “当前执行到 XX 步骤,报错信息是 XXX”,AI 助手能结合他的服务器信息精准排查(比如路径写错、权限不足等) 这样既避免了朋友泄露敏感信息,又能让 AI 助手提供针对性极强的操作步骤,比直接发脚本给 AI 更高效
注意事项 这个两个脚本需要的令牌都放到了环境变量里,这样一是安全,二是github推送的时候不会报错:
服务器Debain12的在你的根目录文件下,也就是/root/.bashrc文件里最后添加如下变量:
1 2 export ESSAY_JWT_TOKEN="eyJhbGQfo" export GITHUB_PAT="ghp_g"
另外,不同系统要求不同,反正现在的这个Debain12 要求使用虚拟环境,在执行python的时候,所以呢,你还要在你的/opt/scripts/venv/bin/activate这个文件中添加如下:
就是在启动定时任务脚本的时候先激活一下变量,反正就是这么个意思,不行的话让你的AI 根据两个脚本帮你写一个定时任务脚本!